
Vision systems, data labelling, and image recognition in AI
Electronic Specifier’s Sam Holland discusses the manual form of artificial intelligence training known as ‘data labelling’ and the fact that many areas of modern vision systems are benefiting from such training by humans.
Exploring ‘data labelling’ and why many AI systems require it
While data labelling has many applications (such as those relevant to language processing and humanoid robotics), this article looks at the term in the context of object detection and object recognition (while later focusing on object classification). Accordingly, the piece considers the role of the two vision systems known as machine vision and computer vision.
The term ‘data labelling’ encompasses the process by which humans can train artificially intelligent software to ‘see’, and therefore recognise and/or analyse, relevant items that fall within the scope of one or more computer-connected cameras. To consider the value of data labelling in vision systems, the following three queries need to be addressed:
• What does the labelling process entail in vision systems?
• What are the different vision systems and their capabilities?
• How can data labelling be further developed to improve vision systems?
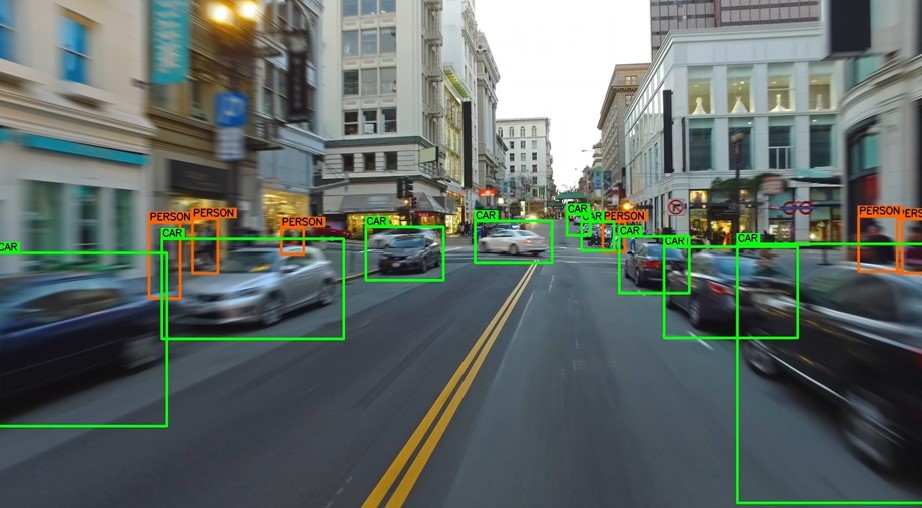
Figure 1. An example of data labelling in vision systems. Pictured: each car and person on a street has been labelled by humans to help train an automotive vision system to differentiate between the two
The labelling process in vision systems
The data labelling process involves the work of people (annotators) who can be anything from dedicated labelling staff through to and including members of a crowdsourced third-party website. The work of these annotators is manual: they are required to view images and/or videos where they can then assign to the many on-screen objects their correct nouns. As just one example of the above, think of how beneficial this mode of programming is to machine learning in autonomous cars (Figure 1): one or more humans view a video of a car driving through a street, and throughout the on-screen journey, every stop sign, traffic light, pedestrian, and so on may be easily labelled by them for a time when the car will eventually be left to its own devices.
Such data labelling processes can often, if not always, be carried out intuitively thanks to the instinctive ways that human brains – as opposed to computer processors – work. More specifically, human brains benefit from intuition and common sense, whereas processors benefit from datasets (the value of which is covered below). Consider, for instance, that you could easily tell apart an orange dog and a fox even though they are both canines of the same colour. Accordingly, if a vision system were to require such information, a human would need to use their common sense to label an orange dog and a fox in order for the given software to be able to form a ‘training dataset’.
Achieving training datasets for vision systems A training dataset is simply one or more pieces of data that are fed into an AI systems’ algorithms so that the given vision system can form analyses and/or predictions based on its trained ability to 'see' the object(s) of interest. How computer vision systems and machine vision systems utilise these training datasets do differ, however. Computer vision systems apply more to analytical forms of image processing (which is why they are proving increasingly helpful in medical diagnoses) whereas machine vision systems are more useful in time-sensitive, industrial contexts (like robot-based picking and packing on the factory floor). Regardless of the chosen applications, the use of data labelling to achieve such training datasets is of course human labour-intensive and time-consuming.
Many software companies therefore stress the importance of using dedicated annotation professionals. The AI organisation Keymakr, for instance, explains that even the capacity of ‘automatic data labelling’ (wherein machines train other machines) is limited in quality and still requires human intervention. The company says that while such labelling may expedite the annotation of "easily identifiable labels", it still yields “a significant amount of errors” that annotators must review and verify. Computer vision and machine vision Computer vision (CV) involves software that analyses a multitude of visual stimuli, such as those that may be digitally scrutinised on a screen or page. Due to the level of data processing demands, these CV systems must be programmed, not only to carry out object detection – but both object recognition and object classification.
• Object detection is the process by which a vision system identifies an object, usually a basic one such as a large piece of industrial equipment.
• Object recognition is the ability to specify multiple objects throughout a diverse image, such as the street picture above.
• Object classification is the process by which a CV system not only recognises objects, but assigns a ‘class’ to the various objects within the given image or video under its observation.
Consider that CV systems that scan radiographs and mammographs have (for decades, in fact) a proven ability to assist in cancer diagnoses. This is a product of computer vision’s capacity to ‘classify’ images of tumours. In other words, CV systems’ use of object classification may be used to ascertain the extent to which a tumour may be benign or malignant, particularly owing to the fact that tumours tend to have different textures depending on which of those two extremes apply.

Figure 2. An example of machine vision: robotic arms that are programmed to recognise parcels and grab them from warehouse shelves
CV systems’ object recognition and classification capabilities are suitable for applications that often take great time, care, and attention. On the other hand, machine vision (MV) (a subset of computer vision) is mainly useful ‘on the factory floor’. It provides machines with a specific industrial application: their cameras ‘see’ the objects of interest, and if the MV system has been programmed correctly by the training datasets provided by data annotators, their processors will respond in accordance with their given tasks and those objects. An example of when an MV system carries out object detection is when a robotic arm distinguishes, and then collects, a required component or other piece of equipment from a warehouse (Figure 2), manufacturing conveyer belt, and so on.
The importance of context in vision systems
On top of the potential that advanced vision systems have to identify, recognise – and even classify – objects, such technology is also further informed by the nature of human reasoning. The term ‘scene understanding’ encompasses the use of semantic reasoning to benefit a vision system’s likelihood of achieving object recognition. After all, even humans may visualise objects better when those objects are viewed in their correct context. As a Frontiers paper explains, people are more likely to recognise a sandcastle on a beach than a sandcastle on a football field.
Moreover, in a Nature paper, ‘Machine vision benefits from human contextual expectations’, the researchers explain that such a similarity (as well as the differences) between artificial intelligence and human reasoning can be exploited in vision systems. In what may be seen as an enhanced form of data labelling, the Nature writers asked participants to indicate their contextual expectations of target objects (such as cars and people) in relation to their associated contexts (such as roads and other urban environments).
The researchers concluded that this contextual annotation and input from humans, combined with a neural network, can enhance the accuracy of object recognition in vision systems. “We demonstrate,” they write, “that … predicted human expectations can be used to improve the performance of state-of-the-art object detectors.”
The combination of human and artificial intelligence
The applications of vision systems vary from the basic industrial level (such as picking and packing on the factory floor) through to and including context-specific cancer diagnoses. Currently, it is clear that the importance of datasets in achieving data labelling and scene context remains a largely human-led operation. Nevertheless, it cannot be ascertained whether artificial intelligence may ever master what humans would call ‘common sense’.
Perhaps, as the rise of automation marches on, it remains possible that data labelling will itself eventually be a job for machines rather than humans. In fact, this would form yet another breakthrough in the already-thriving AI phenomenon known as machine learning.
For more information on contextual and semantic input in vision systems, see the IEEE paper (also linked above): ‘Know Beyond Seeing: Combining Computer Vision with Semantic Reasoning’.

Featured products

MAX17793
Analog Devices Inc.

3V to 80V, 3A, High-Efficiency, Synchronous Step-Down DC-DC Converter
| SKU: | MAX17793 |
|---|---|
| Stock: | 9316 |
| Cost: | $3.64 |

MAX22516
Analog Devices Inc.

IO-Link Data Link Controller with Transceiver and Integrated DC-DC
| SKU: | MAX22516 |
|---|---|
| Stock: | 8000 |
| Cost: | $5.42 |
Product Spotlight
102991834
BeagleBoard

Single Board Computer (SBC), BeagleY-AI
AM67A BeagleY-AI Jacinto 7 AR...
| SKU: | 2820-102991834-ND |
|---|---|
| Stock: | 208 |
| Cost: | $56.24 |
SC1110
Raspberry Pi

Raspberry Pi 5 2GB
The Raspberry Pi 5 2GB model represents a leap for...
| SKU: | 2648-SC1110-ND |
|---|---|
| Stock: | 0 |
| Cost: | $38.33 |
AKX00069
Arduino

Arduino Plug and Make Kit
The Arduino Plug and Make Kit features the ...
| SKU: | |
|---|---|
| Stock: | 968 |
| Cost: | $66.97 |
300361-0011
Molex

MX150 Mid-Voltage MatSealed Female Connector Assembly, Dual Row, 20 Circ...
| SKU: | |
|---|---|
| Stock: | 280 |
| Cost: | $2.51 |