
Robot cheetah teaches itself to run
Back in 2019, MIT (Massachusetts Institute of Technology) debuted its four-legged robot which was the first of its kind to do a backflip. Lightweight and high-power, its motion is reported to rival that of a champion gymnast.
Last month, further news was released that the mini cheetah has learnt to run. Deep learning has enabled the robot itself to run through a process of trial and error. The collaboration of Gabriel B Margolis and Ge Yang’s work resulted in really fast, low-motion behaviour.
This work is new due to its learning-based approach which is used to produce controllers, as opposed to hand-specifying the controllers like people have done in the past (for example, with back flipping). Relatively new to robotic locomotion, its impact is becoming widely recognised.
Achieving such fast and agile locomotion is difficult for a number of reasons. Electronic Specifier talked to Margolis and Yang to find out why.
Hardware
Despite developing their model-free learning software, the duo did not design the hardware. Yang explained: “As soon as you build big, powerful and flexible, it becomes problematic because your controller needs to be able to stand large static ranges for output like motor torques and sensor inputs.
Control becomes problematic as it this hardware needs to be able to handle large dynmic ranges for the motor torques.”
When you run, half the time is spent flying. The faster you run, the more time that is spent in the air. The maximum speed that you can attain is linked intrinsically to the robot’s hardware properties like weight, motor strength and leg length.
The model-based controllers struggle as the robot has trouble estimating its own state when off the ground, whereas Yang and Margolis’ approach does not rely explicitly on state estimation but instead learns to react through trial and error.
In locomotion, the Froude number is defined as:
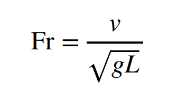
When the Fr (Froude number) equals one, it means that the speed is fast enough and the centripetal force is sufficient for taking off.
The Froude number is a quantity borrowed for fluid dynamics and is used as a rough metric to compare running speed between different hardware.
The Froude number normalises the speed with the robot’s leg length. Yang and Margolis explained that this is considered a more accurate measure than speed and has been used as a metric unit for agility, although is a rough number so not entire principled.
Essentially, Yang and Margolis have pushed the hardware to its limits, something that is only possible with learning-based approaches, not model-based controllers.
The capability of the robot does not follow a linear path. Sometimes to do something harder you need to start from scratch. Using a learning-based approach is one of these paradigm shifts.
State estimation and control
To quote Yang and Margolis, their goal was as follows:
“To learn a policy πθ(.) with parameters θ that takes as input sensory data, velocity commands and outputs joint position commands (see below) which are converted into joint torques by a PD (proportional derivative) controller.
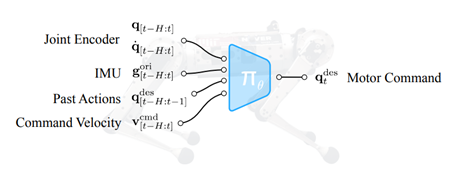
“We constrain the robot to move in a plane and therefore the velocity command (v cmd t ) is three dimensional with linear (v cmd x ), lateral (v cmd y ) and yaw (ω cmd z ) velocity components. Our controller requires no additional state estimation or control subsystems.
Diversity of motion
In most cases of AI and previous studies, the human engineer designs the robot with specific commands and tasks in mind.
As Yang explains: “We use learning-based methods where we learn in the simulator what the robot can actually experience in different scenarios – including failures, or launching itself into the air, or landing on the side.
“The robots are able to experience all of these corner cases in a safe simulation. We take the thing that’s learnt in the simulation into a real robot which allows us to have a diverse set of behaviours and able to adapt to realistic scenarios.”
The key impact of Yang and Margolis’ innovation is that their work offers an existence of proof that this learning-based, sim2real approach is viable. This pipeline can be used to create a diverse set of behaviours, including backflips, and to operate purely from RGB sensors (as currently the robot is blind).

Featured products

MAX17793
Analog Devices Inc.

3V to 80V, 3A, High-Efficiency, Synchronous Step-Down DC-DC Converter
| SKU: | MAX17793 |
|---|---|
| Stock: | 9316 |
| Cost: | $3.64 |

MAX22516
Analog Devices Inc.

IO-Link Data Link Controller with Transceiver and Integrated DC-DC
| SKU: | MAX22516 |
|---|---|
| Stock: | 8000 |
| Cost: | $5.42 |
Product Spotlight
102991834
BeagleBoard

Single Board Computer (SBC), BeagleY-AI
AM67A BeagleY-AI Jacinto 7 AR...
| SKU: | 2820-102991834-ND |
|---|---|
| Stock: | 214 |
| Cost: | $56.24 |
SC1110
Raspberry Pi

Raspberry Pi 5 2GB
The Raspberry Pi 5 2GB model represents a leap for...
| SKU: | 2648-SC1110-ND |
|---|---|
| Stock: | 0 |
| Cost: | $38.33 |
AKX00069
Arduino

Arduino Plug and Make Kit
The Arduino Plug and Make Kit features the ...
| SKU: | |
|---|---|
| Stock: | 968 |
| Cost: | $66.97 |
300361-0011
Molex

MX150 Mid-Voltage MatSealed Female Connector Assembly, Dual Row, 20 Circ...
| SKU: | |
|---|---|
| Stock: | 280 |
| Cost: | $2.51 |